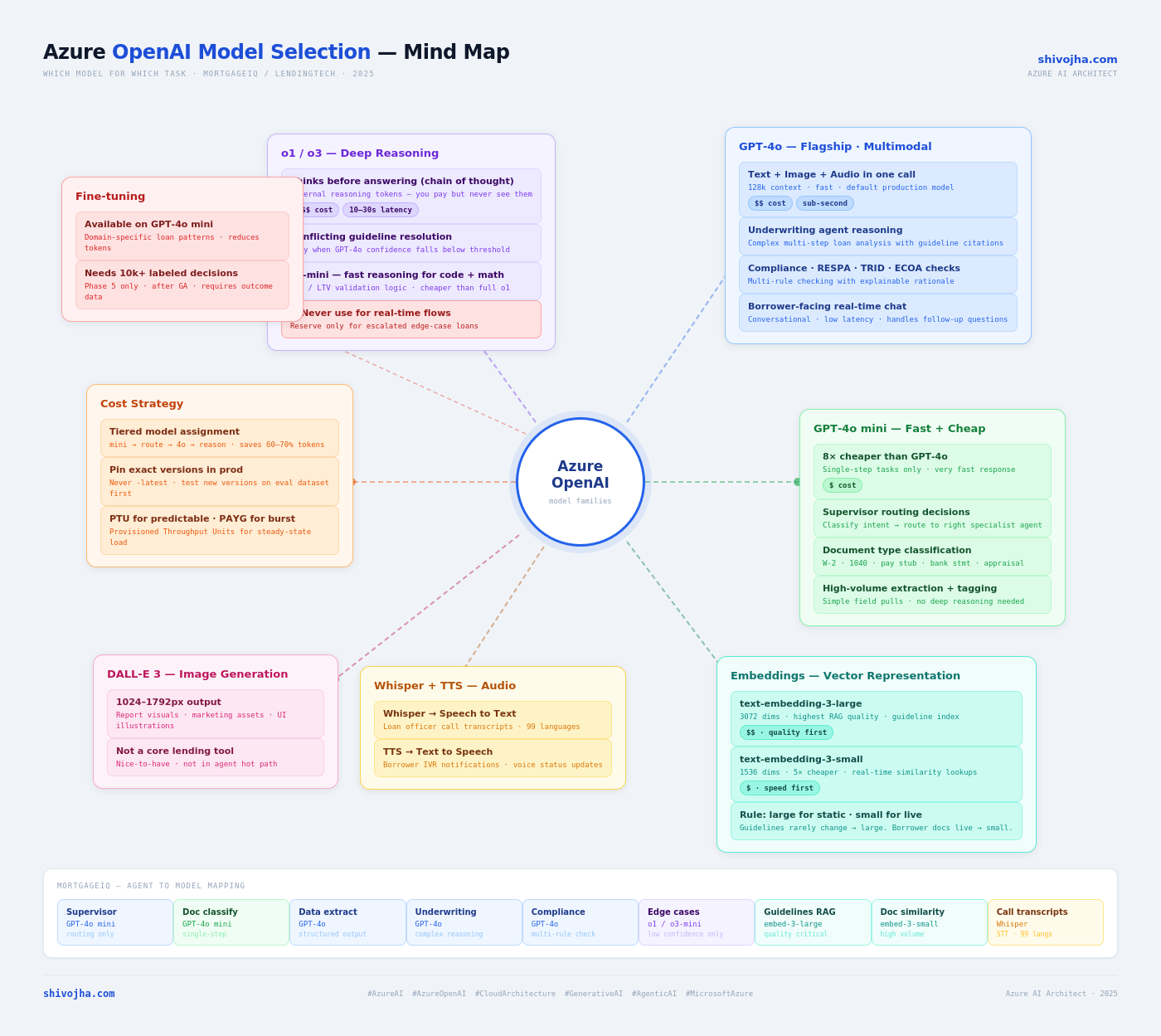
There are four model families in Azure AI Foundry. Most teams use one.
That's not a criticism — GPT-4o is an exceptional model. But defaulting it for every task is the AI equivalent of hiring a senior architect to classify your mail. The result is a system that works in the demo and becomes financially unsustainable in production.
Azure AI Foundry offers four distinct model families, each optimized for a different job. Understanding the boundary between them is what separates a prototype from a production architecture.
The Four Families
GPT-4o — The General Workhorse
Job: Complex reasoning, multimodal input, structured output, anything requiring more than one logical step.
The "o" stands for omni — one model call handles text, images, and audio. In practice this means you can pass a scanned W-2 image directly to GPT-4o and ask it to extract structured data. No OCR pre-processing step. No separate vision model call.
When to use it:
- Document analysis that requires reasoning (underwriting guidelines, compliance checks)
- Structured output generation where field accuracy matters
- Multi-step reasoning over retrieved context (RAG responses)
- Any task where a wrong answer has downstream consequences
Pricing: ~$2.50/1M input tokens, ~$10/1M output tokens (gpt-4o-2024-11-20)
GPT-4o mini — The Cost-Efficient Workhorse
Job: Any task that requires no more than one logical step.
GPT-4o mini is roughly 8× cheaper per token than GPT-4o and significantly faster. It makes more mistakes on complex multi-step reasoning. That's fine — most tasks in a real system don't require complex reasoning.
The rule of thumb: if the task can be described as classification, routing, or simple extraction, use mini.
When to use it:
- Intent routing ("which agent should handle this?")
- Document type classification ("is this a W-2 or a pay stub?")
- Simple field extraction ("what is the employer name?")
- Filtering and triage before expensive model calls
Pricing: ~$0.15/1M input tokens, ~$0.60/1M output tokens
The math that matters: If you have 10,000 classification calls per day, running them on GPT-4o costs ~$250/month. Running them on GPT-4o mini costs ~$22/month. That's $2,700/year per single task type.
o1 / o3 — The Reasoning Models
Job: Hard multi-step problems where getting it wrong has high cost.
These models are fundamentally different in architecture. Before generating an answer, they internally produce a chain of reasoning tokens — a "thinking" phase you never see but do pay for. This hidden reasoning is what makes them dramatically better at problems that require planning, conflicting constraint resolution, or legal/regulatory interpretation.
The tradeoffs are significant:
- Latency: 10–30 seconds vs. sub-second for GPT-4o
- Cost: 3–5× higher than GPT-4o
- No system prompt on some versions — you frame context differently
When to use them:
- Edge cases where guidelines conflict (e.g., FHA vs. conventional rules that overlap)
- Complex compliance review requiring multi-rule traversal
- Fraud pattern analysis across multiple correlated signals
- Any task where GPT-4o's confidence falls below a threshold
The escalation pattern — not the default model:
GPT-4o underwriting analysis
→ confidence score < 0.75
→ escalate to o1-mini
→ return o1 analysis with reasoning trace
You never run the whole pipeline on o1. You use it as the escalation target for the cases GPT-4o flags as uncertain. This preserves the 10–30s latency hit for the fraction of calls that actually need it.
Pricing: ~$15/1M input tokens, ~$60/1M output tokens (o1)
Embedding Models — Not Generative
Job: Turn text into vectors for semantic search. Not for generation.
Two variants matter:
| Model | Dimensions | Use case |
|---|---|---|
| text-embedding-3-large | 3,072 | Main guideline RAG index — quality matters |
| text-embedding-3-small | 1,536 | High-volume / real-time indexing |
The large model is worth the small premium for your primary knowledge base. The quality difference in retrieval recall is real and measurable. Use the small model for anything that's high-volume or latency-sensitive — borrower document embeddings, session-level vectors, real-time chunking.
Pricing: $0.13/1M tokens (large), $0.02/1M tokens (small)
Whisper and TTS — The Utility Models
- Whisper — Speech-to-text. Loan officer call recordings, IVR transcription.
- TTS — Text-to-speech. Borrower status update calls, voice IVR response.
These are point solutions. They don't need a routing strategy — you use them when you need audio I/O.
The Full Model Map
Model Assignment for a Multi-Agent Loan Processing System
This is the assignment I use for MortgageIQ and the pattern I'd apply to any regulated lending workflow:
| Agent / Task | Model | Reason |
|---|---|---|
| Supervisor routing | GPT-4o mini | One-step: which agent handles this? |
| Document classification | GPT-4o mini | One-step: W-2, pay stub, or bank statement? |
| Data extraction | GPT-4o | Structured output, some reasoning needed |
| Underwriting analysis | GPT-4o | Complex reasoning, guideline interpretation |
| Compliance review | GPT-4o | Multi-rule checking, citation required |
| Fraud signal analysis | GPT-4o | Pattern reasoning across multiple inputs |
| Edge case escalation | o1-mini | Conflicting guidelines, low-confidence cases |
| RAG index — guidelines | text-embedding-3-large | Quality matters, infrequently updated |
| RAG index — borrower docs | text-embedding-3-small | High volume, constantly updated |
| Call transcription | Whisper | Loan officer recordings |
| Borrower voice IVR | TTS | Status update phone calls |
The pattern: cheap and fast at the edges, powerful at the core, reasoning-heavy only at escalation.
The Version Pinning Rule
This is non-negotiable in a regulated environment.
Never use gpt-4o-latest or gpt-4o without a date suffix in production. Azure AI Foundry aliases like gpt-4o-latest update silently when OpenAI releases a new version. Behavior changes. Your evaluation scores change. In a lending environment, a model update could shift your approve/decline distribution — and you'd never know why.
Your Foundry deployment should always specify the exact version:
{
"model": "gpt-4o-2024-11-20",
"deployment_name": "gpt-4o-prod-v1"
}
When a new version is released:
- Deploy it as a new Foundry deployment (don't update the existing one)
- Run it against your golden evaluation dataset
- Compare groundedness scores, accuracy, latency, cost
- Promote if it passes — roll back if it doesn't
This is the same discipline you apply to any dependency upgrade. The model is a dependency.
What I've Seen Fail
1. GPT-4o for everything. The most common pattern. Works fine until you look at the bill. A 10,000-call/day classification pipeline on GPT-4o costs ~$250/month. On mini it's ~$22. That's $2,700/year for one task you routed to the wrong model.
2. o1 as the default reasoning model. Teams see the benchmark scores and set o1 as their primary model. Then they wonder why every API call takes 20 seconds. o1's latency is a feature — it means the model is actually thinking. That's exactly what you want for edge case escalation. It's not what you want for your main inference path.
3. Unpinned model versions in production.
gpt-4o-latest updated. The system started declining loans it used to approve. No code changed. No deployment happened. The model changed silently. Three days of debugging to find the root cause. Pin your versions.
4. One embedding model for everything. Teams use text-embedding-3-large for both their static guideline index (great) and their real-time borrower document pipeline (expensive and unnecessarily slow). The small model is 85% as accurate at 15% of the cost. For real-time indexing, that tradeoff is obvious.
5. No model routing layer. Everything goes directly to the LLM with no routing or confidence-gating. When you add a routing layer — even a simple one — you unlock model substitution without touching application code. The routing layer is where cost optimization lives.
The Architecture Implication
Model selection is not a configuration choice. It's an architecture decision.
The teams that get this right build a model routing layer between their application and Azure AI Foundry — a lightweight service that maps task type to model version, enforces token budgets, and gates escalation. The application code never hard-codes a model name. When pricing changes, when a new model ships, when a task needs to be rerouted — you change one configuration, not ten services.
This is the same principle as the IRetrievalService abstraction in MortgageIQ: the application depends on the interface, not the implementation. The model is an implementation detail.