Problem
Mortgage borrowers face hundreds of questions before closing — credit scores, DTI limits, down payments, closing costs. Generic AI answers are unreliable because the model generates from training data, not from actual loan guidelines. The answer to "What credit score do I need for an FHA loan?" changes depending on lender, year, and loan type. A hallucinated answer in a financial context isn't just wrong — it erodes trust and exposes the institution to liability.
The challenge isn't connecting to an LLM. It's connecting the LLM to the right knowledge, reliably, with a traceable evidence chain.
Solution
MortgageIQ is a RAG-based loan assistant built on Azure OpenAI GPT-4o. It answers borrower questions by first retrieving relevant passages from a curated, version-controlled loan knowledge base — then composing a grounded prompt that tells the model: answer only from what you've been given, and cite your source.
Three properties distinguish this from a ChatGPT wrapper:
- Groundedness — every answer is drawn from retrieved document chunks, not the model's parametric memory
- Traceability — every response includes structured
sources[]metadata; borrowers can click through to the exact source document - Auditability — the knowledge base lives in the repository alongside the code; every change goes through a pull request review
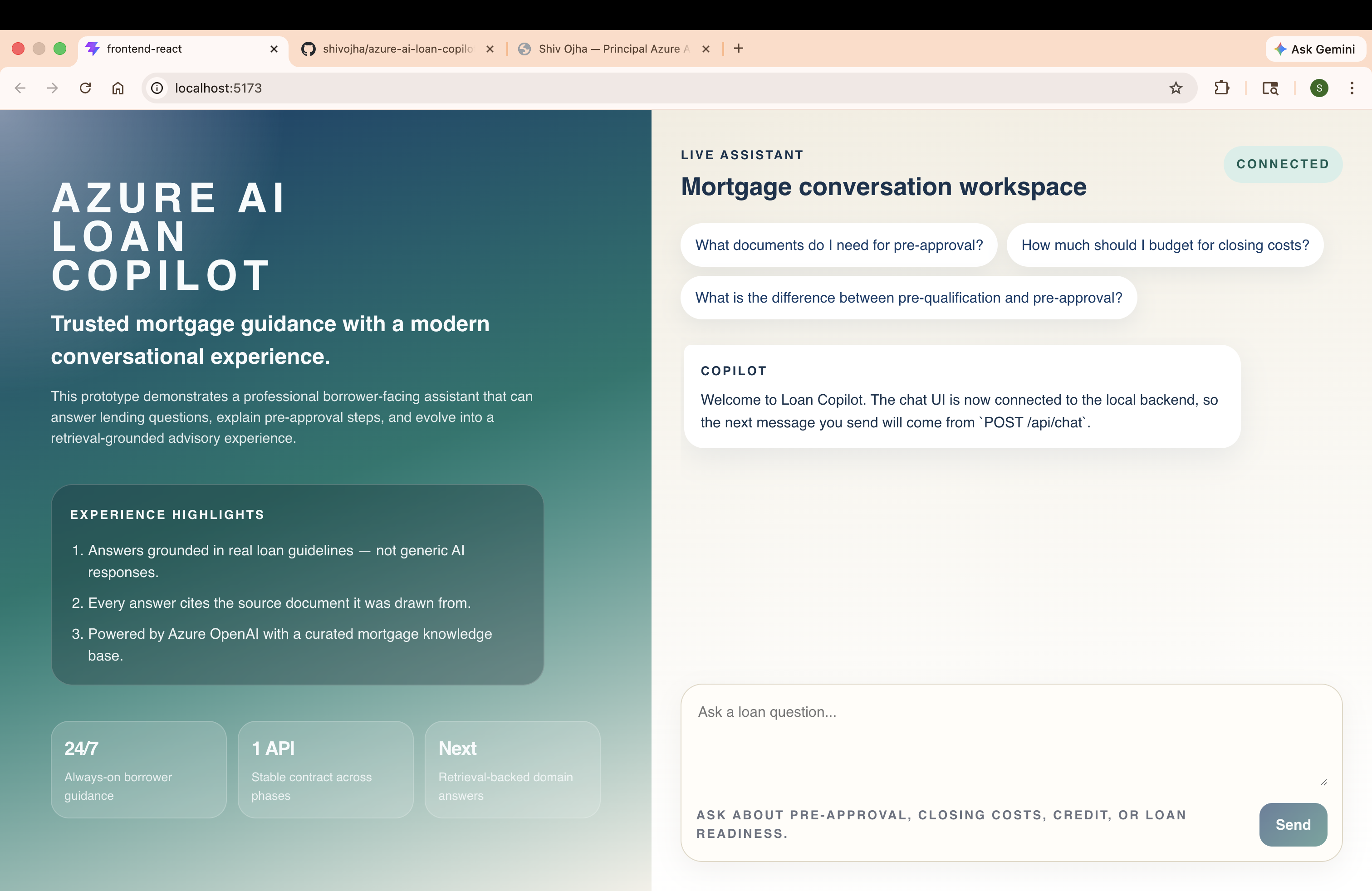
What It Answers (Phase 4A — Basic)
The knowledge base covers the five most common pre-approval question categories:
| Borrower asks | Knowledge base source |
|---|---|
| What credit score do I need for an FHA loan? | fha-loan-requirements.md — Credit Score Requirements |
| How much should I save for closing costs? | closing-costs.md — Closing Cost Breakdown |
| What documents do I need for pre-approval? | pre-approval-process.md |
| What is the difference between pre-qual and pre-approval? | pre-approval-process.md |
| How does my credit score affect my interest rate? | credit-score-guidelines.md |
Questions outside this domain — live rates, underwriter decisions, property appraisals — fall through to the model's general knowledge with a disclaimer. This boundary is deliberate: the system is designed to be confidently grounded within scope and transparently limited outside it.
Architecture
System Context
The request flow has one rule: the model never answers from memory alone.
Component Architecture
The retrieval layer is intentionally separated from the API layer behind an interface. This is the architectural decision that makes Phase 4B (Azure AI Search) a one-line dependency injection swap.
How RAG Works — Inside the Retrieval Pipeline
This is where the architectural decisions live. The retrieval pipeline has four stages: chunking, tokenization, scoring, and token budgeting. Understanding each stage explains both why the system works and exactly where it breaks.
Stage 1: Chunking
Each knowledge base document is split into sections at ## markdown headers. This produces semantically coherent chunks — each chunk covers one concept (Credit Score Requirements, Down Payment Requirements, etc.) rather than arbitrary character counts.
fha-loan-requirements.md → 6 chunks
├── fha loan requirements — Credit Score Requirements
├── fha loan requirements — Down Payment Requirements
├── fha loan requirements — Debt-to-Income Ratio
├── fha loan requirements — Loan Limits
├── fha loan requirements — Mortgage Insurance Premium
└── fha loan requirements — Property Requirements
Across 5 files, this produces approximately 28 chunks held in memory and scored on every query.
Why section-based chunking? Fixed-size chunking (e.g., 512 tokens) splits mid-sentence and loses section context. Semantic chunking at section boundaries keeps related content together — a borrower question about FHA credit scores gets the full Credit Score Requirements section, not a fragment that starts mid-paragraph.
Stage 2: Tokenization and Scoring
The query "What credit score do I need for an FHA loan?" is tokenized with stop word filtering:
Raw terms: [what, credit, score, do, i, need, for, an, fha, loan]
After filter: { credit, score, need, fha, loan } ← 5 meaningful terms
Each chunk is scored by keyword overlap:
score = overlapping query terms in chunk / total query terms
For the FHA Credit Score chunk:
"credit" ✓ "score" ✓ "need" ✗ "fha" ✓ "loan" ✓
score = 4/5 = 0.80
Top-scoring chunks for this query:
| Chunk | Score |
|---|---|
| fha loan requirements — Credit Score Requirements | 0.80 |
| credit score guidelines — Credit Score Ranges | 0.80 |
| fha loan requirements — Down Payment Requirements | 0.40 |
| conventional loan requirements — Credit Score Reqs | 0.40 |
| closing costs — What Are Closing Costs | 0.00 → filtered |
Stage 3: Token Budget Enforcement
Before assembling the prompt, each surviving chunk is checked against a 2,000-token budget. The budget prevents context overflow — GPT-4o's context window is large, but unbounded context injection degrades answer quality and drives up cost.
Chunk 1: ~155 tokens ✓ (running total: 155)
Chunk 2: ~185 tokens ✓ (running total: 340)
Chunk 3: ~140 tokens ✓ (running total: 480)
→ All 3 fit. Budget enforced before prompt assembly.
Stage 4: Prompt Composition
The retrieved chunks are injected into the system message as structured context. The model is instructed to answer only from the provided context and to cite its source:
System:
You are a helpful mortgage and loan assistant. Give concise, practical guidance,
note when rules vary by lender or location, and avoid pretending to know
borrower-specific facts you were not given.
Use the following loan knowledge to answer accurately:
[fha loan requirements — Credit Score Requirements]
FHA loans require a minimum credit score of 580 to qualify for the 3.5% down payment option.
Borrowers with scores between 500–579 may be eligible with 10% down...
[credit score guidelines — Credit Score Ranges]
...
If the provided context does not address the question, answer from your general
knowledge and say so.
User: What credit score do I need for an FHA loan?
This pattern — grounded system prompt, constrained generation instruction, explicit citation requirement — is what separates a production RAG system from a demo. The model can only hallucinate if it ignores the system message; the system is designed to make that path explicit and detectable.
Request Flows
Grounded Answer (Retrieval Hit)
Graceful Degradation (Retrieval Miss)
The retrieval-miss tag is a first-class observability signal. It tells you which questions fall outside your knowledge base — which is exactly the input you need to decide what to add next.
Code
The Retrieval Abstraction
The most important line of code in this project is the interface:
// src/RetrievalService/IRetrievalService.cs
public interface IRetrievalService
{
Task<IReadOnlyList<RetrievalResult>> QueryAsync(
string question,
CancellationToken cancellationToken);
}
Every retrieval backend — local keyword search today, Azure AI Search in Phase 4B, a vector database in Advanced — implements this interface. AzureOpenAiChatResponder depends on IRetrievalService, not on any concrete retrieval implementation. The upgrade path is a dependency injection registration change:
// Phase 4A (Basic) — local keyword search
builder.Services.AddSingleton<IRetrievalService>(sp =>
new LocalFileRetriever(sp.GetRequiredService<IOptions<RetrievalOptions>>().Value));
// Phase 4B (Intermediate) — Azure AI Search hybrid retrieval
builder.Services.AddSingleton<IRetrievalService>(sp =>
new AzureSearchRetriever(sp.GetRequiredService<IOptions<AzureSearchOptions>>().Value));
AzureOpenAiChatResponder, the REST endpoints, ChatResult, and the React frontend do not change between phases.
Prompt Composition
// src/ChatApi/Services/AzureOpenAiChatResponder.cs
private static string BuildSystemPrompt(string basePrompt, IReadOnlyList<RetrievalResult> sources)
{
if (sources.Count == 0)
return basePrompt;
var contextBlock = string.Join("\n\n", sources.Select(s =>
$"[{s.SourceName}]\n{s.Snippet}"));
return $"{basePrompt}\n\nUse the following loan knowledge to answer accurately:" +
$"\n\n{contextBlock}\n\n" +
$"If the provided context does not address the question, " +
$"answer from your general knowledge and say so.";
}
The citation requirement in the system prompt is reinforced by returning structured sources[] from the retrieval layer — the UI renders these as clickable chips regardless of what the model says. Citations are retrieval metadata, not model output. This eliminates the hallucination risk in the citation chain entirely.
Tradeoffs
These are the tradeoffs accepted deliberately in Phase 4A. Each one is a conscious scope decision, not a gap.
| Area | What was accepted | Why | Fixed in |
|---|---|---|---|
| Retrieval quality | Keyword overlap only — "cash upfront" won't match "closing costs" | Zero infrastructure; proves the RAG composition pattern end-to-end | Phase 4B (Azure AI Search vector + BM25 hybrid) |
| Chunking at query time | Files re-read and chunked on every request | Simplicity over performance; acceptable at demo scale | Phase 4B (pre-built persistent index) |
| Token estimate | length / 4 approximation, no real tokenizer | Avoids a tokenizer dependency in Phase 4A; accurate enough for English prose | Phase 4B |
| No streaming | Full response buffered before sending to UI | Frontend simplicity; streaming requires coordinated backend + frontend change | Advanced |
| No semantic cache | Every query calls Azure OpenAI | Low volume; cache adds Redis/Cosmos dependency not justified at demo scale | Advanced |
| No auth | API has no authentication | Local development only | Advanced |
| No evaluation pipeline | Response quality tracked via tags only | Tags provide sufficient signal at this scale; formal RAGAS eval deferred | Advanced |
The tradeoff that matters most for Phase 4A to 4B: keyword retrieval misses semantic queries. "How much cash do I need upfront?" fails to match "closing costs" because no words overlap after tokenization. This is a known, bounded limitation — not a bug. It's the exact problem Azure AI Search's vector retrieval solves.
Phase Roadmap
The abstraction investment in Phase 4A — the IRetrievalService interface — exists entirely to make this progression smooth. The architecture is designed to evolve, not to be replaced.
Phase 4B changes: Swap LocalFileRetriever → AzureSearchRetriever. Add text-embedding-3-small for query embedding. CI-triggered re-indexing on data/loan-kb/ file changes. No changes to ChatApi, no changes to the React frontend.
Tech Stack
| Layer | Technology | Version | Role |
|---|---|---|---|
| Frontend | React | 19.2.4 | Chat UI, message rendering, source chips |
| Frontend | TypeScript | 5.9 | Type-safe API contract |
| Frontend | Vite | 8.x | Dev server, build, HMR |
| Backend | ASP.NET Core | .NET 10 | REST API, static file serving |
| Backend | C# | 13 | Application language |
| Backend | Azure.AI.OpenAI SDK | 2.1.0 | Azure OpenAI client |
| AI | Azure OpenAI GPT-4o | — | Chat completion |
| Retrieval | LocalFileRetriever | Phase 4A | Keyword scoring, section chunking, token budget |
| Knowledge Base | Markdown files | 5 documents | Versioned in repo, human-auditable |
Impact
This project demonstrates the foundational pattern that every enterprise GenAI system is built on: grounding LLM output in a controlled knowledge source with a traceable evidence chain. The techniques here — RAG, section-based chunking, token budget management, system prompt composition, retrieval abstraction — are the same patterns used at production scale in regulated financial and healthcare systems.
The architecture is sized for a demo. The decisions are sized for production.
Related Blog Articles
Each concept in this project is covered in depth as a standalone post:
- RAG Architecture — RAG Is Not the Hard Part. Retrieval Is.
- Prompt Engineering — Prompt Engineering Is Software Engineering. Treat It That Way.
- Azure GenAI Stack — The Enterprise GenAI Stack on Azure: What Actually Works in Production
- FinOps for AI — FinOps for AI: Why Your GPT-4o Bill Will Surprise Your CFO